
Blog post
While visiting a customer last week (a large SaaS platform company), we started to have an interesting discussion around Service Level Agreements (SLAs) during which he encouraged me to write this blog.
When I was tasked with setting up the QoS Team at DoubleClick in 1999, the primary mission was to setup a monitoring team (internal, external, etc.) and the secondary mission was actually an accidental one: to manage our SLAs.
This became a hot priority in 2001, we paid out over $1 million (in real money) in penalties for SLA violations to a single customer. Basically, someone on our side signed a contract with insane service commitments like 100% uptime.
When we started to tackle this problem we were novice and had to ramp up quickly to stop those kind of penalty payments—we were in a crisis mode. My CFO was breathing down my neck every day with the same question, over and over again: “Are we going to breach anything today?”
Today, I am sharing my journey of how I took control of our SLAs as a ASP (back when SaaS was still an Application Service Provider), and everything you need to know to do the same.
Part 1: What are SLAs?
An SLA is a contractual agreement between a vendor and a customer, stating that the vendor will deliver on agreed upon terms. The SLA is the legal umbrella, under which you have one or more Service Level Objective(s) (SLO) which describe the Service, measurement methodology, and objective (uptime, speed, transaction / seconds, etc.). The definition below describes how an SLA covers the customer and the vendor:

- Customer: An SLA benefits the client by providing objective grading criteria and protection from poor service.
- Vendor: An SLA benefits the supplier by providing a way of ensuring that the correct expectations are set, performance will be judged fairly and that the supplier is incentivized to improve quality of services.
- For SLAs to be implemented, we also agreed on the following key principles:
- Attainable
- Repeatable
- Measurable
- Meaningful
- Mutually acceptable
Part 2: Ground zero, discovery
The first few weeks were spent compiling the list of all the contracts, extracting SLAs, SLOs, penalties, and putting that in a database.
Then I went to start the education process with the business stakeholders, legal, and our leadership.
As you can see, I focused on end-user experience based SLAs from an early stage.

Part 3: Establishing an SLA is more than just putting a few sentences in the contract.
The reason we paid $1 million is that there was no SLA Management System in place.
We started then by building a Service Level Management practice that relied on 4 pillars: Administration, Monitoring, Reporting, and Compliance (AMRC).

Then we sat down with the business partners, customers, legal, and finance team and created a process to avoid costly mistakes in the future, an SLA lifecycle. We reviewed the SLM quarterly:

We then used our in-house Data Scientists to run simulations on the risk to breach SLAs based on the historical data we had from our monitoring tools. You do not want to set SLA that will be breached every day.

We also ran multiple “what-if” scenarios on availability vs. revenue and the impact at various hours of the day and days of the week:

We even created an online tool (2001) for our sales team to be able to request an SLA portfolio for a customer that would be reviewed and approved by our QoS team; think of this as an “SLA desk.”

Part 4: External SLAs and internal SLAs.
In these early stages of this project, we quickly discovered a major glitch: the external SLAs were not matching the internal ones. And that, in my opinion, was going to be a huge mistake—how can we ever achieve such goals, talk the same language between the tech, business, and customers when everything was so different? Customers would ask for ad serving uptime and our tech group would use servers availability!
So, we aligned our external and internal SLOs and made the internal objectives (the targets) very very high. This was a huge victory because it allowed us on a daily basis to rely on one set of metrics to understand our SLA risk position, but also to drive operational excellence. Our tech group (Ops, Engineering, etc.) became sensitive to the notion of a business SLA and started to care very much about not breaching them.
Part 5: Monitoring
For availability and performance, we relied on three synthetic products; internally, Sitescope was running in 17 datacenters, and two external synthetic products. We wanted to have as many data points as possible from as many tools as possible. The stakes were just too high to not invest in multiple tools. This entire SLM project was not cheap to implement and run on an annual basis, but I also knew the cost of not doing it right the hard way.
For monitoring it became clear to us that we needed to test as frequently as possible from as many vantage points as possible:
- When you test your SLOs end points every 1 hour, you have to wait 59 minutes after each check! So you could be inflicting yourself with false downtime.
- You want many data points to ensure statistical significance. You could use small datasets, but you will tend to have lower power and precision. Bigger datasets are also better for dealing with False Positives and False Negatives.
Part 6: Performance (speed) monitoring
One of our biggest difficulties was finding an effective way to measure the performance of third-party providers – and implementing that technique in SLAs.
The challenge was that clients would look at their site performance and notice spikes and they would attribute it to our system, meanwhile our performance chart would not show any problems. We couldn’t correlate the two charts, therefore we couldn’t come to an agreement whether it was our problem or someone else’s problem.

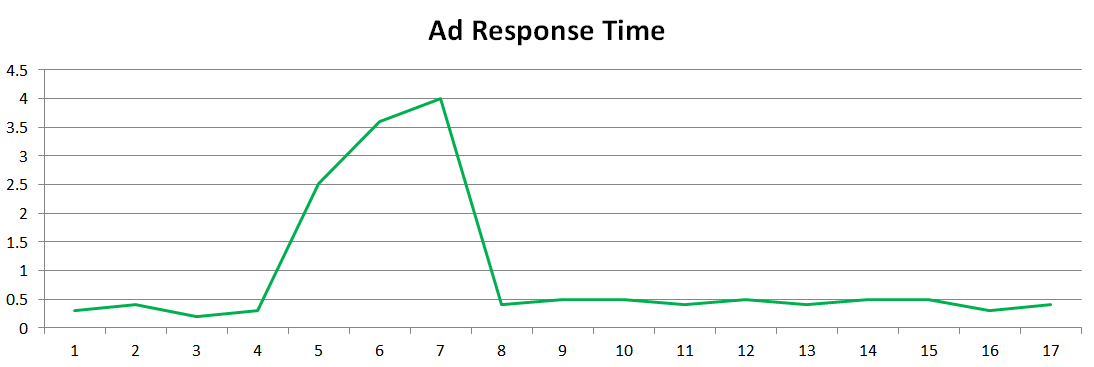
We created a methodology we called Differential Performance Measurement (DPM).
The philosophy behind DPM was to be able to measure the performance and availability of Doubleclick’s services as accurately as possible and its impact on the pages of our customers, making sure we were responsible and accountable for the things we had control over to eliminate the finger-pointing.
The methodology added context to the measurements. DPM introduced clarity and comparison, removing absolute performance numbers from the SLAs.
Recipe for Differential Performance Measurement (example with an advert.):
1- Take two pages, one without ads and one with one ad call.
- Page A = without ad
- Page B = with ad
2- Make sure the pages do not contain any other third-party references (CDNs, etc.).
3- Make sure the page sizes (in KB) are the same.
4- “Bake” – Measure response times for both pages and you get the following metrics:
- Differential Response (DR) will be (Response Time of page B) minus (Response Time of page A)
- Differential Response Percentage (DRP) = DR / A. (e.g. If Page A is 2 seconds, and Page B is 2.1 seconds, DR is 0.1 second, and DRP is 0.1/2=0.05 or 5%)
With this methodology, we were able to eliminate noise introduced by:
- Internet-related issues that were out of our control (fiber cuts, etc.)
- Monitoring agent issues (which raises the separate topic of monitoring your monitoring services)
- Other third parties

- Scenario 1: The ad serving company is having performance problems and negatively impacting the customer’s site performance. The vendor breached the SLA threshold from Time 4 to Time 8.
- Scenario 2: The website is having performance problems that are not caused by the ad serving company.
Part 7: Reporting
Because of that huge payout, the entire SLM project had a lot of visibility that extended all the way to CEO. We reported monthly on our compliances and our internal SLAs, breaches were detected in real time (thanks to a clever tool DigitalFuel, that, sadly, no longer exists.).
The external SLOs were just a subset of the internal SLOs; when we were done in late 2001, we were tracking over 100 OLAs.

I cannot stress enough that if you are going to embark on this journey, you better report a lot! But, also make sure the reports are actionable (Green, Yellow, Red).
Example of a monthly Report:

Example of our daily reporting during our Daily Health Check meeting:

A Culture of Quality emerged at DoubleClick because everyone was aligned around these business service metrics. No one wanted to breach SLAs, no one wanted to let down the customer.
Part 8: Conclusions
After doing this exercise of implementing what I would consider in the early 2000s to be a comprehensive SLM process, we were able to:
- Manage hundreds of contracts with up to five SLOs.
- Offer a wide range of SLAs that were scalable (adding new products).
- Reduce the financial risks to our company.
- Manage our reputation and credibility by giving meaningful SLAs and reporting on them with accuracy and integrity.
- Real time alerts of compliance breach. Knowing ahead of time that an SLA will be breached was incredible; we would know that adding four minutes of downtime will breach 12 contracts and result in $X, so Ops took steps to stop releases or anything that could have an impact on uptime.
Some people do not believe in SLAs. Bad SLAs are the ones that some companies put in the contract without real penalties or real measurements. I always see the SLAs that guarantee 0% packet loss, but if you ask how it’s measured, you quickly realize that it’s useless—this is exactly what gives SLAs a bad reputation.
I believe that SLAs are a great way to align customers and vendors, reduce frictions, and stop the finger-pointing. But, customers also need to do their jobs and ask for useful SLAs. The point is that you want to hold the vendors accountable, not to drive them out of business. You want them to feel the pain of not doing a good job when they do not deliver the service for which they are being payed.
As the “Cloudification” of our world expands, SLAs are here to stay and they are going to become even more prevalent. Customers of these services like cloud servers, cloud applications (Office365, Salesforce, etc.), services (DNS, CDN, Security, etc.) will see customers demanding more meaningful SLAs, stricter enforcement, and more penalties. This is the only way forward.
Summary
This is some text inside of a div block.




