
Blog post
Cloudflare's most recent outage took significant portions of the Internet offline, and it reflects a pattern that has become routine in digital infrastructure.
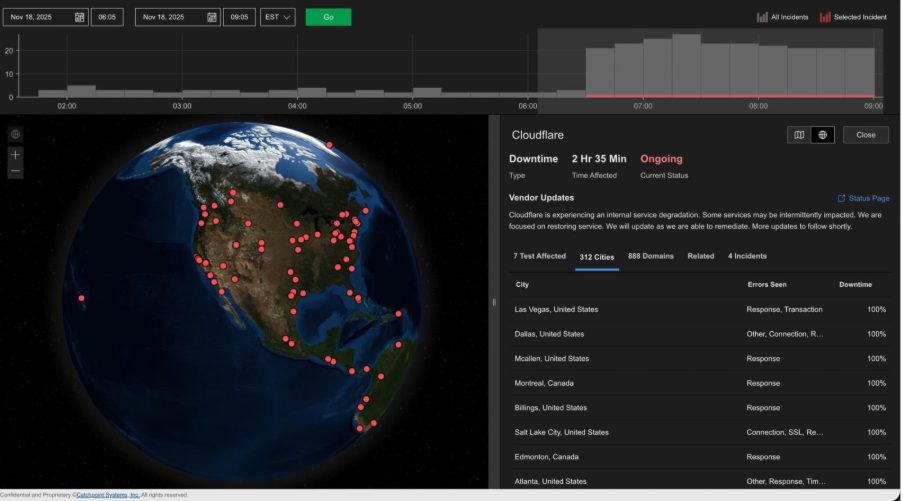
Catchpoint Internet Sonar dashboard showing Cloudflare's ongoing outage in real time
Key Takeaways
- Cloud and CDN outages from providers like Cloudflare, AWS, and Azure are recurring events, not anomalies. Resilience planning should treat them as expected.
- Single-vendor CDN strategies concentrate risk at the layer closest to the end user. Multi-CDN architectures improve reliability, performance, and cost flexibility.
- Monitoring tools must be independent from the systems they monitor. When a provider goes down, your visibility shouldn't go down with it.
- Resilience requires deliberate architectural choices: dependency mapping, failover testing, runbooks, and independent observability from diverse global vantage points.
Outages at major cloud and content delivery network (CDN) providers are now a recurring reality. For most organizations, the question isn't whether outages will happen, but when, and how prepared teams are to respond.
The Dangerous Illusion of Invincibility
Many organizations architect their entire digital presence around the assumption that cloud providers and CDN services will stay up. When a provider goes down and takes everything with it, teams that bet entirely on that vendor's reliability have no fallback and no warning.
Consider the failures we've witnessed recently. In July 2025, Cloudflare went down again. On October 20, it was AWS's turn. Fortnite and Roblox players were suddenly locked out. Duolingo learners watched their streaks disappear. Snapchat's 400 million daily users couldn't send messages or view stories. Even Eight Sleep mattresses malfunctioned: some overheated or got stuck upright when their cloud connections failed.
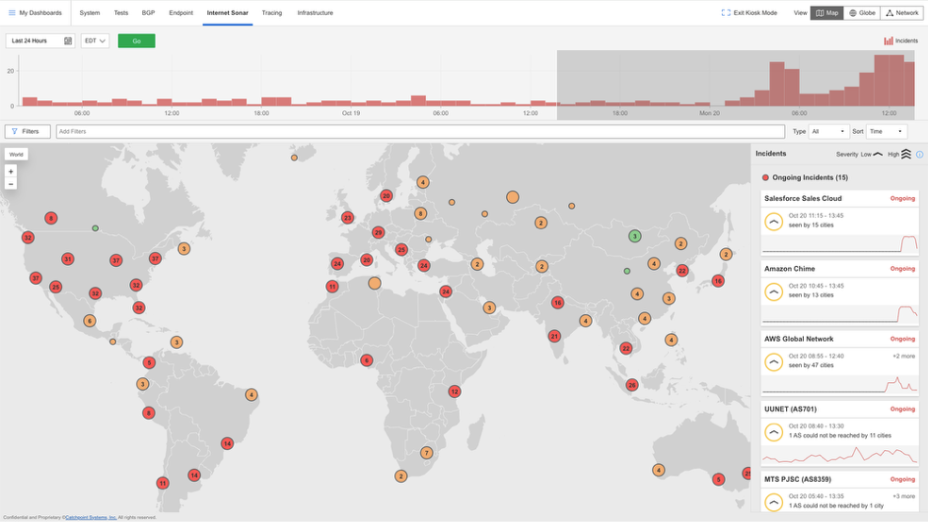
Catchpoint Internet Sonar dashboard showing AWS's October outage
Just nine days later, on October 29, 2025, Microsoft Azure's Front Door CDN had a global outage that lasted more than eight hours. The result was widespread latency, timeouts, and errors across Microsoft 365, Outlook, Teams, Xbox Live, and many websites hosted on Azure, as well as corporate applications that had a component (an API, cloud service, or authentication service) hosted on Azure.

Catchpoint Internet Sonar dashboard showing Azure's recent global outage
None of these outages are isolated events. They're evidence that cloud service failures are a persistent reality.
Cloud deployments carry the same failure modes as any infrastructure: misconfigurations, human error, failed updates, and cascading dependencies.
Digital systems are critical for daily life, and those systems are complex, interconnected, distributed, and interdependent. There's no cloud magic that protects systems just because they're hosted in the cloud.
The Mindset That Makes Organizations Vulnerable
Recently, someone shared this perspective:
"I'm on Cloudflare. I don't need anything else. I don't need monitoring."
That sentiment captures the heart of the issue. These massive Internet disruptions keep happening for reasons that go beyond technical failures. The deeper problem is a mindset: a belief that using Cloudflare, AWS, Azure, or any major platform somehow makes companies immune to failure. When people rely on a "trusted" provider, they feel justified in skipping resilience planning.
Moving Past the Assumption of Vendor Infallibility
CDNs have been critical for performance acceleration since the late 1990s. They reduce latency, absorb traffic spikes (and DDoS attacks), and cache content closer to users. Over time, though, organizations stopped treating CDNs as tools and started assuming they were fail-proof. That assumption is where risk accumulates.
Even the best CDNs have outages. DNS delays, BGP leaks, TLS misconfigurations, and, in Cloudflare's case, an oversized threat management file can all result in prolonged downtime. If you're locked into a single CDN without a fallback plan, there's nowhere left to redirect your traffic when disaster strikes.
The Multi-Cloud Contradiction
There's an ironic twist here. Enterprises invest heavily in multi-cloud strategies. They spread compute, storage, and databases across AWS, Azure, and Google Cloud, investing in complex architecture and ongoing management. Yet, for the CDN layer that actually connects users to their apps, they typically choose one vendor.
Most enterprises wouldn't run critical backend systems in a single availability zone. Yet many still route all user-facing traffic through a single CDN, concentrating risk at the layer that matters most to the end user.
The impact goes beyond downtime. CDN outages frustrate users, erode brand credibility, and can negatively affect revenue and customer trust in seconds.
When Your CDN Is Also Your Eyes
The risk increases when companies depend on a single CDN for both critical delivery and performance monitoring. When a single vendor handles both delivery and monitoring, it can't give you independent confirmation of its own failures.
When AWS's massive outage struck, it didn't just take down cloud services, apps, and enterprise platforms. It also knocked out many of the monitoring systems organizations depend on for real-time answers. A number of third-party observability platforms lost visibility or functionality precisely when organizations needed them most.
There's a straightforward principle to follow: your monitoring must be independent from the system being monitored.
This is one of the core reasons LogicMonitor built its platform with Catchpoint, part of the LogicMonitor platform, running on an independent global agent network. When the services you depend on go down, your visibility into what's happening shouldn't go down with them.
Redundancy and Resilience: A Strategic Advantage
Adopting a multi-vendor architecture is a deliberate strategy that drives real business value in performance, cost, and control across several dimensions:
- Regional Performance Optimization: Different CDN providers excel in different regions. One may dominate in Europe. Another performs best in Southeast Asia. Using the best performer for each geography means better outcomes for users everywhere.
- Vendor Leverage and Cost Optimization: Multiple providers mean you retain bargaining power. If your CDN's price goes up or service falters, you have the flexibility to move workloads. Being able to shift traffic also encourages competitive pricing.
- Feature Flexibility: Providers specialize in varied areas, including edge compute, video delivery, TLS offload, and security features. A multi-CDN approach lets you choose the right platform for each job.
- Resilience Through Redundancy: Automated failover and smart routing help multi-CDN systems maintain service, even during major outages. If one provider goes down, traffic shifts instantly, often before users notice. Organizations that pre-tested multi-CDN failover during the Azure Front Door outage recovered in seconds. Those relying on a single vendor experienced the full eight-plus hours of downtime.
Intelligent traffic steering: When traffic is critical, implementing traffic steering brings resilience along with the ability to make dynamic, real-time adjustments to optimize for user experience and cost. A multi-vendor strategy isn't foolproof. It can fail without the right visibility and processes to support it. At LogicMonitor, we use Cloudflare as a primary CDN, but we also maintain backup accounts. Having a second, backup CDN isn't that hard to set up.
Building Resilience: A Practical Framework
Resilience doesn't arise by itself. It requires deliberate architectural choices and operational discipline.
- Establish a Chief Resilience Officer Position: It's time for companies to take this seriously and appoint a CRO who reports to the board. It needs to be an independent position with the authority to make the right investments and changes to minimize risk to the business.
- Become Aware of Your Dependencies: Map out your dependencies, and the dependencies of your dependencies. When Azure went down, Docusign went down too. This is a serious issue for real estate businesses, for example, and most likely a dependency they hadn't accounted for.
- Plan for Failure: Apply chaos engineering practices: define the steady state for your systems, introduce controlled failure scenarios, and confirm that both systems and teams respond as designed. Regular fault injection builds the muscle memory that matters during real incidents.
- Design Redundancy for Every Dependency: Eliminate single points of failure. Be prepared for any component of the system to fail. Distribution should be strategic, reflecting workload, geography, and risk.
- Create Runbooks for Every Possible Failure: It's important to document the process and desired actions when incidents happen, based on their scope and severity.
- Test Failover Routinely: Simulate outages on a regular schedule. Confirm that both systems and staff respond well in emergencies. Practice makes sure no critical step is overlooked when customers depend on you.
- Establish Independent Visibility: Use monitoring tools that give you independent visibility into every dependency and the ability to react quickly, minimizing impact to the business. Don't rely only on vendor dashboards.
- Understand Global and Local Performance: Users in different regions can have very different experiences. Service outages can be regional. Performance variations can become meaningful quickly. Monitor from diverse global vantage points to understand the real-world user experience, not only global uptime metrics.
The Path Forward
The organizations that handle outages well build resilience before they need it, mapping dependencies, distributing risk, and validating failover before incidents happen.
Redundancy has become essential to resilience. And with LogicMonitor's unified platform, combining LM Envision for infrastructure observability, Catchpoint for Internet Performance Monitoring, and Edwin AI for intelligent analysis and action, teams can see across the full path from user to code and respond to disruptions before they become business-impacting events.
To learn how LogicMonitor helps teams monitor Internet dependencies and build resilience into their digital operations, request a demo today.
Summary
Cloudflare’s latest outage, like those on AWS and Azure before it, shows outages aren’t a surprise, but an expectation. Relying on a single CDN is a recipe for disaster. True resilience demands multi-CDN strategies, routine failover testing, independent performance monitoring, and a mindset shift away from convenience toward preparedness. Outages are normal; chaos is optional.
This is some text inside of a div block.




