Blog post
Blog Post
Cloudflare Outage: A Case for Better CDN Reliability
Although the outage was remediated quickly, the impact was felt on a global scale, as Cloudflare took down hundreds of popular websites with it.
This year is quickly becoming a treasure trove for lessons in incident detection and resolution. Over the last few months, multiple outages have brought the internet to the brink of chaos, exposing the vulnerabilities inherent in the current digital architecture.
Catchpoint detected another Cloudflare outage yesterday, July 2, 2019. The incident that began at 9:43 AM ET and lasted 30 minutes, taking down hundreds of popular websites with it.
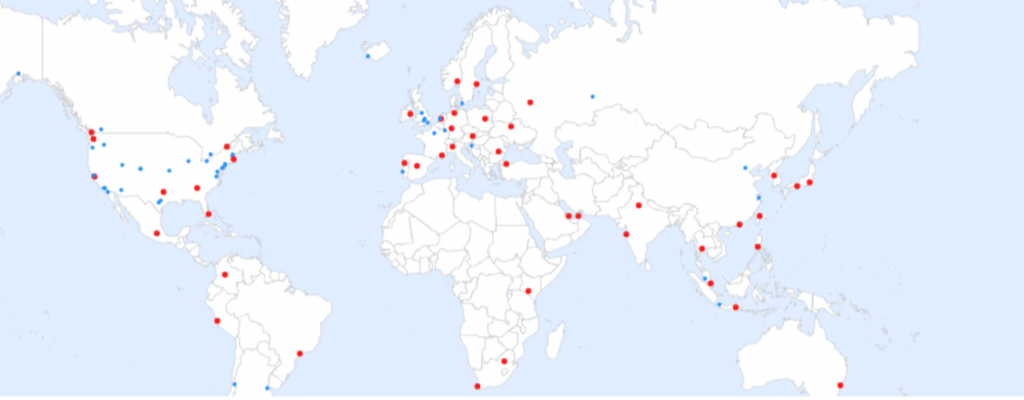
Although the outage was remediated quickly, the impact was felt on a global scale. The red dots in the geo-heat map below denote failures across multiple countries (blue dots indicate successful tests).
The Cloudflare status page was updated at 9:52 AM ET, around nine minutes after Catchpoint first detected the issue.

The websites that were impacted displayed a HTTP 502/Bad Gateway error:
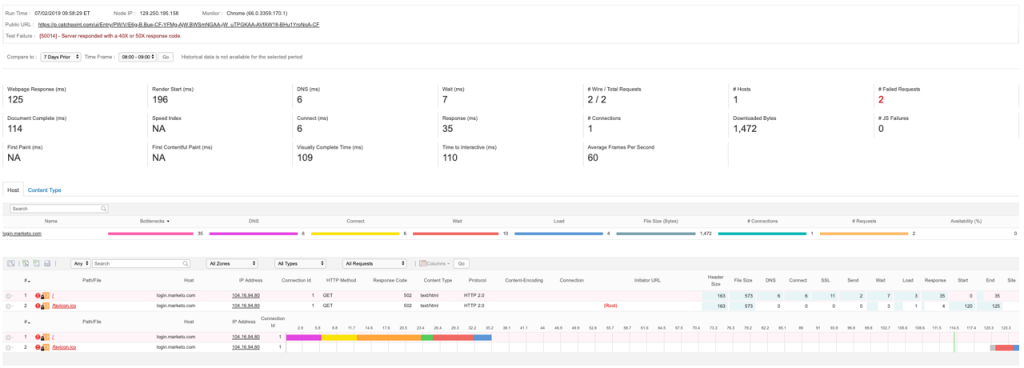
According to the analysis published by Cloudflare on their blog, the issue occurred during a routine deployment of Web Application Firewall (WAF) rules. A misconfigured rule pushed CPU usage to 100%, which caused the 502 errors. Cloudflare fixed the issue once the root cause was identified.
“At 1402 UTC we understood what was happening and decided to issue a ‘global kill’ on the WAF Managed Rulesets, which instantly dropped CPU back to normal and restored traffic. That occurred at 1409 UTC.”
How severe was the impact?
The short duration of the outage does not mean the damage was negligible. To start with, Cloudflare serves almost 700K customers and at the peak of the issue there was an 82% drop in traffic. So a sizeable number of customers experienced unexpected downtime.
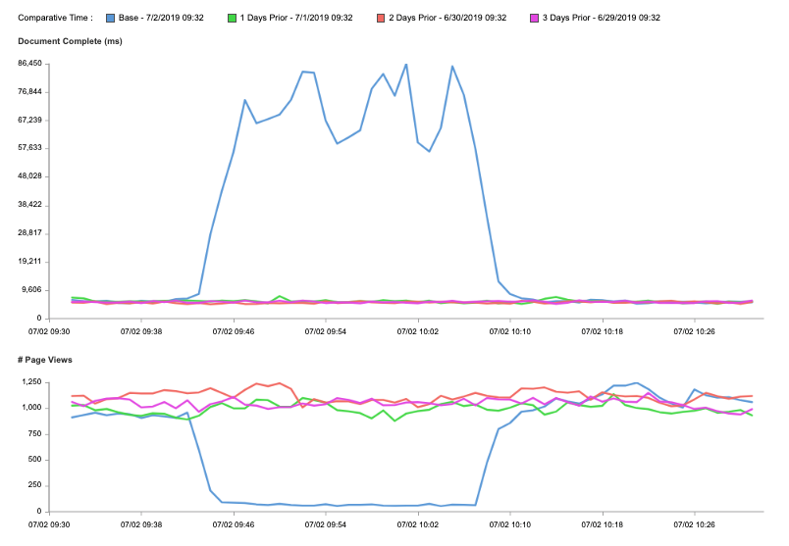
The graph below is an example of the impact the outage had on Catchpoint customers. We can see the sharp increase in document complete time, which corresponds to a sharp decline in page views during the incident.
Outages are inevitable. Always be Prepared.
Considering the growing complexity of the digital space, the fact that outages can happen anytime is enough reason to do everything it takes to mitigate the impact of such incidents. And while Cloudflare was able to respond to the incident relatively quickly with quick detection and repair, there’s no telling how long the next one will be.
You take into account the possibility of a long and sustained outage as a worst-case scenario when planning your own monitoring and failover strategies.
- A complete Digital Experience Monitoring (DEM) strategy will help detect and identify issues faster.
- A failover strategy that includes multiple CDNs will help you quickly mitigate the damage.
It is essential to monitor every component in the application delivery chain. CDNs deliver critical data and reliability can quickly turn into a liability if you don’t monitor. CDN monitoring involves more than just checking health of the CDN provider. Comprehensive CDN monitoring must account for:
- DNS
- CDN mapping
- CDN-to-Origin latency
- Cache hit-or-miss ratio
1. DNS Monitoring
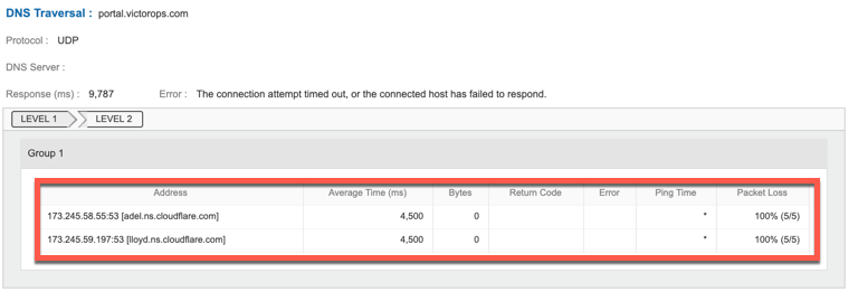
CDNs can introduce DNS related challenges. When an organization deploys a CDN, their DNS is relegated to their managed DNS provider, who in turn relegates it to the CDN. Over the years we have seen many breaks in such chains leading to errors. In the image below, DNS resolution failed with packet loss due to issues with the CDN.
2. CDN Mapping
To optimise content delivery, it is vital to understand how the CDN maps to the end-user location. Catchpoint provides a CDN mapping dashboard that monitors:
- CDN edge locations mapped to end-user locations
- Amount of Wait Time experienced at the CDN edge location
The CDN mapping dashboard (image below) uses Response Time to highlight the health of the CDN provider across multiple geo-locations. You can easily identify latency in mapping and have your provider optimize the path to improve performance.

3. CDN-to-Origin latency
Every layer in the CDN must be monitored for latency. It is important to pinpoint where the bottleneck is as it can be in any of the following level:
- End user to CDN edge server
- Within CDN (child, parent)
- CDN to orgin
- Within origin
The image below compares performance at three different levels – end user to CDN (in red), within CDN, and edge server to CDN/Origin. The variation in performance between each level is significant and can help in content delivery optimization.
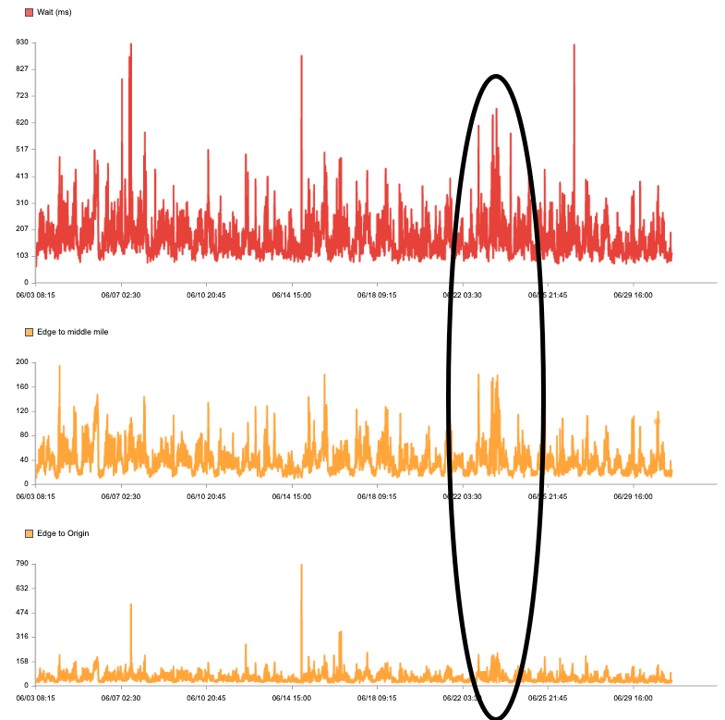
4. Cache Hit-or-Miss Ratio
A cache hit/miss refers to where the content was retrieved from: the CDN cache or the origin server. This matters because latency can be introduced depending on where the content is served from; monitoring the cache hit/miss ratio provides insights into the CDN configuration, which further helps optimize performance..
Leverage Multiple CDNs for Resiliency and Optimal Performance
In addition to CDN monitoring, a multi-CDN strategy should be a priority. Relying on a single CDN puts the entire application at risk in case of an outage like we saw on Tuesday. When you have multiple CDNs handling content, it is easier to maintain availability if there is an issue with one of the CDNs, as you can reroute your traffic through the other(s) until the primary comes back online.
Summary
The Cloudflare outage was a reminder that:
- Outages WILL happen! Don’t be caught unaware when it does.
- All outages have financial implications no matter the duration.
Lessons learned:
- Detecting faster is the first step in reducing mean time to repair (MTTR).
- A faster MTTR minimizes damage and maintains positive end-user experience.
- Monitoring every layer and every component is vital to performance.
- Comprehensive CDN monitoring is the first step in building CDN reliability.
- A multi-CDN strategy will guarantee better uptime.
What can you do right now to prepare for another CDN related outage?
- Manually re-route traffic to origin (not ideal)
- Use multi-CDN strategy
- Use load balancing services
- Use DNS-based load balancing to reroute traffic to origin
July 3, 2019



Kameerath Kareem
This is some text inside of a div block.